SSE/SSE2/AVX/AVX2 Notes
AVX/AVX2/SSE/SSE2指令集
数据类型
| 数据类型 | 描述 |
|---|---|
| __m128 | 包含4个float类型数字的向量 |
| __m128d | 包含2个double类型数字的向量 |
| __m128i | 包含若干整形数字的向量 |
| __m256 | 包含8个float类型数字的向量 |
| __m256d | 包含4个float类型数字的向量 |
| __m256i | 包含若干整形数字的向量 |
- 每一种类型,2个下划线开头,接着一个m,然后是vector的长度
- 若向量类型是d结尾,则向量存的double类型的数字。若无后缀则为float类型的数字。
- 整型的向量可以包含各种类型的整型数,如char,short,unsigned long long。也即, __m256i可以包含32个char,16个short,8个int,4个long类型。这些整型数可以是有符号和无符号类型。
函数名约定
_mm<bit_width>_<name>_<data_type>
<bit_width>:向量长度,对于128位向量,参数为空,256位向量,参数为256<name>:内联函数的算数操作简述<data_type>:函数主参数的数据类型p/s:分别为packed和scalar。packed指令是对整个向量暂存器的所有数据都进行计算。而scalar只计算向量暂存器的低位中的数据进行计算。s/d:s为float类型,d为double类型
ps:包含float类型的向量
pd:包含double类型的向量
epi8/epi16/epi32/epi64:包含8位/16位/32位/64位的有符号整数
epu8/epu16/epu32/epu64:包含8位/16位/32位/64位的无符号整数
si128/si256:未指定的128位或者256位向量
m128/m128i/m128d/m256/m256i/m256d:当输入向量类型与返回向量的类型不同时,标识输入向量类型
示例1:_mm256_srlv_epi64,即使不知道srlv的含义,_mm256前缀说明该函数返回一个256-bit向量,后缀_epi64表示参数包含多个64-bit整型数。
示例2:_mm_testnzc_ps,其中_mm意味着该函数返回一个128-bit向量,后缀ps表示该参数包含float类型。
写一个AVX程序
首先需要包含immintrin.h头文件。
hello_avx.cpp
1 | |
函数初始化
标量初始化函数
| 数据类型 | 描述 |
|---|---|
| _mm256_setzero_ps/pd | 返回一个全0的float/double类型向量 |
| _mm256_setzero_si256 | 返回一个全0的整型向量 |
| _mm256_set1_ps/pd | 用一个float类型数填充向量 |
| _mm256_set1_epi8/epi16/epi32/epi64x | 用整型数填充向量 |
| _mm256_set_epi8/epi16/epi32/epi64x | 用一个整形数初始化向量 |
| _mm256_set_ps/pd | 用8个float或4个double类型数字初始化向量 |
| _mm256_set_m128/m128d/m128i | 用2个128位的向量初始化一个256位向量 |
| _mm256_setr_ps/pd | 用8个float或者4个double的转置顺序初始化向量 |
| _mm256_setr_epi8/epi16/epi32/epi64x | 用若干个整形数的转置顺序初始化向量 |
setzero
1 | |
输出:
1 | |
set1
1 | |
输出:
1 | |
set
1 | |
输出:
1 | |
setr
1 | |
输出:
1 | |
从内存中加载数据
| 数据类型 | 描述 |
|---|---|
| _mm256_load_ps/pd | 从对齐的内存地址加载float/double向量 |
| _mm256_load_si256 | 从对齐的内存地址加载整形向量 |
| _mm256_loadu_ps/pd | 从未对齐的内存地址加载浮点向量 |
| _mm256_loadu_si256 | 从未对齐的内存地址加载整形向量 |
| _mm_maskload_ps/pd | 根据掩码加载128位浮点向量的部分 |
| _mm256_maskload_ps/pd | 根据掩码加载256位浮点向量的部分 |
| _mm_maskload_epi32/64(只在avx2中支持) | 根据掩码加载128位整形向量的部分 |
| _mm256_maskload_epi32/64(只在avx2中支持) | 根据掩码加载256位整形向量的部分 |
调用:
1 | |
若要处理的float数组长度为11不能被8整除。那么最后5个浮点数需要置0。或者使用上表中的_maskload_。
_maskload_函数有两个参数:内存地址、相同元素数目的整型向量作为返回。整型向量中每个元素的最高位为1,返回的向量中对应元素是从内存中读取的。若整型向量中每个元素最高位为0,则返回的向量对应元素置0。
mask_load.cpp
读入8个int到向量,最后3个应该置0。使用了_mm256_maskload_epi32,第二个参数应为__m256imask向量。该mask向量包含5个整型,其最高位是1,剩下3个整型的最高位置0.
1 | |
输出:
1 | |
说明:
- 负整型的最高位总为1。所以mask vector选用5个负数,3个正数
_mm256_maskload_epi32是AVX2函数,因此用gcc编译加-mavx2参数
算术本质
加减法
| 数据类型 | 描述 |
|---|---|
| _mm256_add_ps/pd | 对两个浮点向量做加法 |
| _mm256_sub_ps/pd | 对两个浮点向量做减法 |
| (2)_mm256_add_epi8/16/32/64 | 对两个整形向量做加法 |
| (2)_mm256_sub_epi8/16/32/64 | 对两个整形向量做减法 |
| (2)_mm256_adds_epi8/16 (2)_mm256_adds_epu8/16 | 两个整数向量相加且考虑内存饱和问题 |
| (2)_mm256_subs_epi8/16 (2)_mm256_subs_epu8/16 | 两个整数向量相减且考虑内存饱和问题 |
| _mm256_hadd_ps/pd | 水平方向上对两个float类型向量做加法 |
| _mm256_hsub_ps/pd | 垂直方向上最两个float类型向量做减法 |
| (2)_mm256_hadd_epi16/32 | 水平方向上对两个整形向量做加法 |
| (2)_mm256_hsub_epi16/32 | 水平方向上最两个整形向量做减法 |
| (2)_mm256_hadds_epi16 | 对两个包含short类型的向量做加法且考虑内存饱和的问题 |
| (2)_mm256_hsubs_epi16 | 对两个包含short类型的向量做减法且考虑内存饱和的问题 |
| _mm256_addsub_ps/pd | 加上和减去两个float类型的向量、(在偶数位置减去,奇数位置加上,获最后得目标向量。) |
前面有一个(2),代表函数只在AVX2中支持。
_add_/_sub_函数和_adds_/_subs_函数的区别在于。s表示饱和,即当结果需要更多的内存来保存结果也能存下。
例1:一个向量包含signed bytes,因此每个元素最大值是127(0x7F).若有98加85的操作,结果是183(0xB7).
- 若用
_mm256_add_epi8,溢出部分会被忽略存储结果为**-73(0xB7)** - 若用
_mm256_adds_epi8,结果会被限制在最大值即127(0x7F)
例2:两个signed short整型向量,最小值为-32768。若计算-18000-19000,结果为-37000(0xFFFF6F78 as a 32-bit integer)
- 若用
_mm256_sub_epi16,溢出会被忽略存储结果为 28536(0x6F78) - 若用
_mm256_subs_epi16,结果会被限制在最小值**-32768(0x8000)**
_hadd_/_hsub_函数为水平加减。即向量相邻元素做加减,而不是向量间做加减。
而在水平方向上做加减法的意思如下图:
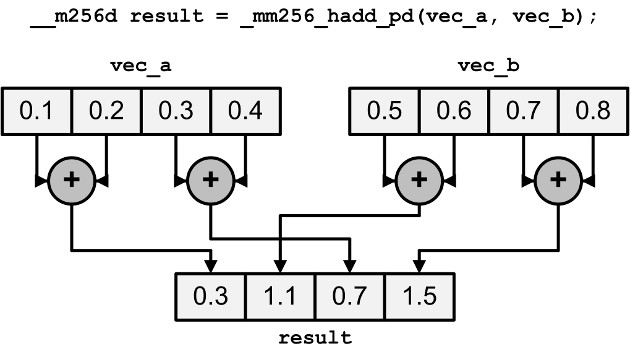
乘除法
| 数据类型 | 描述 |
|---|---|
| _mm256_mul_ps/pd | 对两个float类型的向量进行相乘 |
| (2)_mm256_mul_epi32 (2)_mm256_mul_epu32 | 将包含32位整数的向量的最低四个元素相乘 |
| (2)_mm256_mullo_epi16/32 | Multiply integers and store low halves |
| (2)_mm256_mulhi_epi16 (2)_mm256_mulhi_epu16 | Multiply integers and store high halves |
| (2)_mm256_mulhrs_epi16 | Multiply 16-bit elements to form 32-bit elements |
| _mm256_div_ps/pd | 对两个float类型的向量进行想除 |
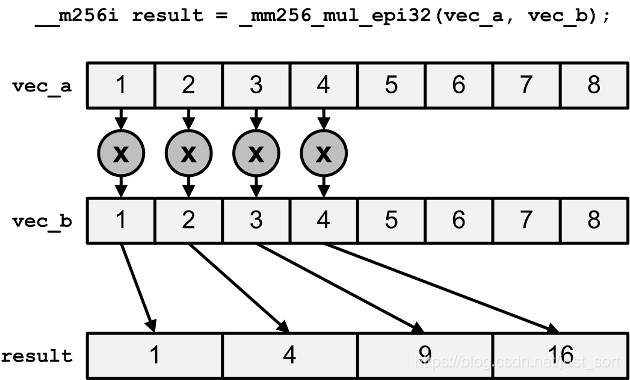

复合运算
| 数据类型 | 描述 |
|---|---|
| (2)_mm_fmadd_ps/pd/ (2)_mm256_fmadd_ps/pd | 将两个向量相乘,再将积加上第三个。(res=a*b+c) |
| (2)_mm_fmsub_ps/pd/ (2)_mm256_fmsub_ps/pd | 将两个向量相乘,然后从乘积中减去一个向量。(res=a*b-c) |
| (2)_mm_fmadd_ss/sd | 将向量中最低的元素相乘并相加(res[0]=a[0]*b[0]+c[0]) |
| (2)_mm_fmsub_ss/sd | 将向量中最低的元素相乘并相减(res[0]=a[0]*b[0]-c[0]) |
| (2)_mm_fnmadd_ps/pd (2)_mm256_fnmadd_ps/pd | 将两个向量相乘,并将负积加到第三个。(res = -(a * b) + c) |
| (2)_mm_fnmsub_ps/pd/ (2)_mm256_fnmsub_ps/pd | 将两个向量相乘,并将负积加到第三个 (res = -(a * b) - c) |
| (2)_mm_fnmadd_ss/sd | 将两个向量的低位相乘,并将负积加到第三个向量的低位。(res[0] = -(a[0] * b[0]) + c[0]) |
| (2)_mm_fnmsub_ss/sd | 将最低的元素相乘,并从求反的积中减去第三个向量的最低元素。(res[0] = -(a[0] * b[0]) - c[0]) |
| (2)_mm_fmaddsub_ps/pd/ (2)_mm256_fmaddsub_ps/pd | 将两个矢量相乘,然后从乘积中交替加上和减去(res=a*b+/-c) |
| (2)_mm_fmsubadd_ps/pd/ (2)_mmf256_fmsubadd_ps/pd | 将两个向量相乘,然后从乘积中交替地进行减法和加法(res=a*b-/+c)(奇数次方,偶数次方) |
unpack、permute、shuffle、blend
unpack
permute
| 数据类型 | 描述 |
|---|---|
| _mm_permute_ps/pd _mm256_permute_ps/pd | 根据8位控制值从输入向量中选择元素 |
| (2)_mm256_permute4x64_pd/ (2)_mm256_permute4x64_epi64 | 根据8位控制值从输入向量中选择64位元素 |
| _mm256_permute2f128_ps/pd | 基于8位控制值从两个输入向量中选择128位块 |
| _mm256_permute2f128_si256 | 基于8位控制值从两个输入向量中选择128位块 |
| _mm_permutevar_ps/pd _mm256_permutevar_ps/pd | 根据整数向量中的位从输入向量中选择元素 |
| (2)_mm256_permutevar8x32_ps (2)_mm256_permutevar8x32_epi32 | 使用整数向量中的索引选择32位元素(浮点和整数) |
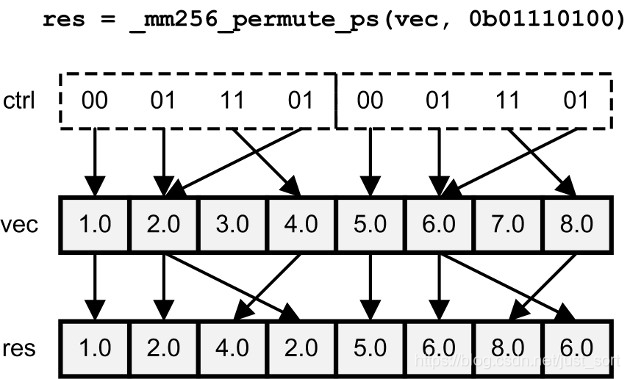
shuffle
| 数据类型 | 描述 |
|---|---|
| _mm256_shuffle_ps/pd | 根据8位值选择浮点元素 |
| _mm256_shuffle_epi8/ _mm256_shuffle_epi32 | 根据8位值选择整数元素 |
| (2)_mm256_shufflelo_epi16/ (2)_mm256_shufflehi_epi16 | 基于8位控制值从两个输入向量中选择128位块 |
对于_mm256_shuffle_pd,只使用控制值的高4位。如果输入向量包含int或float,则使用所有控制位。对于_mm256_shuffle_ps,前两对位从第一个矢量中选择元素,第二对位从第二个矢量中选择元素。
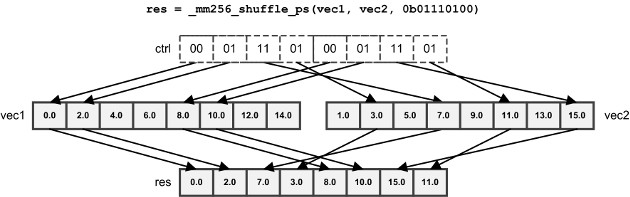
blend
Reference
https://software.intel.com/sites/landingpage/IntrinsicsGuide/
https://software.intel.com/en-us/articles/introduction-to-intel-advanced-vector-extensions/
https://www.codeproject.com/Articles/874396/Crunching-Numbers-with-AVX-and-AVX
https://blog.triplez.cn/avx-avx2-learning-notes/#Shuffling
https://github.com/Triple-Z/AVX-AVX2-Example-Code
https://blog.csdn.net/just_sort/article/details/94393506
https://www.jianshu.com/p/64ef4d304e17
https://www.officedaytime.com/tips/simd.html
https://github.com/microsoft/SPTAG/blob/master/AnnService/inc/Core/Common/DistanceUtils.h
CPU指令集介绍
https://blog.csdn.net/gengshenghong/article/details/7006817
在C/C++代码中使用SSE等指令集的指令(1)介绍
https://blog.csdn.net/gengshenghong/article/details/7007100
在C/C++代码中使用SSE等指令集的指令(2)参考手册
https://blog.csdn.net/gengshenghong/article/details/7008682
在C/C++代码中使用SSE等指令集的指令(3)SSE指令集基础
https://blog.csdn.net/gengshenghong/article/details/7008704
在C/C++代码中使用SSE等指令集的指令(4)SSE指令集Intrinsic函数使用
https://blog.csdn.net/gengshenghong/article/details/7010615
在C/C++代码中使用SSE等指令集的指令(5)SSE进行加法运算简单的性能测试
https://blog.csdn.net/gengshenghong/article/details/7011373
Writing C++ Wrappers for SIMD Intrinsics (1-5)
https://johanmabille.github.io/blog/2014/10/09/writing-c-plus-plus-wrappers-for-simd-intrinsics-1/
https://johanmabille.github.io/blog/2014/10/10/writing-c-plus-plus-wrappers-for-simd-intrinsics-2/
https://johanmabille.github.io/blog/2014/10/10/writing-c-plus-plus-wrappers-for-simd-intrinsics-3/
https://johanmabille.github.io/blog/2014/10/13/writing-c-plus-plus-wrappers-for-simd-intrinsics-4/
https://johanmabille.github.io/blog/2014/10/25/writing-c-plus-plus-wrappers-for-simd-intrinsics-5/
Performance Considerations About SIMD Wrappers
https://johanmabille.github.io/blog/2014/11/20/performance-considerations-about-simd-wrappers/
Aligned Memory Allocator
https://johanmabille.github.io/blog/2014/12/06/aligned-memory-allocator/
Ubuntu SSE指令集 编程实例—复数乘法与共轭乘法
https://blog.csdn.net/jxwxg/article/details/53091376
AVX2整数向量运算
https://blog.csdn.net/tigerisland45/article/details/54671536
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!