BP神经网络原理和简明理解
单个神经元结构
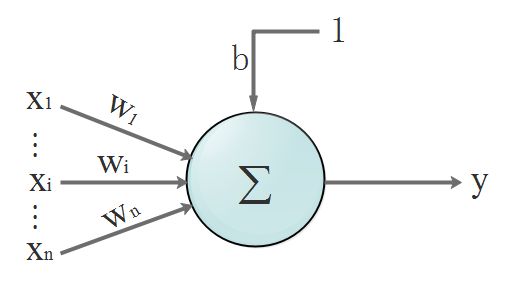
输入:$x_1,x_2,…,x_n$
输出:$y$
输入和输出的关系(函数):$y = (x_1\ast w_1+x_2\ast w_2+…+x_n\ast w_n+)+b = \sum_{i=1}^n x_i\ast w_i+b$,其中$w_i$是权重
将输入用矩阵表示:$X = [x_1,x_2,…,x_n]^T,X为一个n行1列的矩阵$
将权重用矩阵表示:$W=[w_1,x_2,…,w_n]$
那么输出可以表示为:$y=[w_1.w_2,…,w_n] \cdot [x_1,_2,…,x_n]^T+b=WX+b$
激活函数
激活函数是一类复杂的问题,为便于理解这里有几条重要的特性:
- 非线性:即导数不是常数,不然求导之后退化为直线。对于一些画一条直线仍然无法分开的问题,非线性可以把直线掰弯,自从变弯以后,就能包罗万象了。
- 几乎处处可导:数学上,处处可导为后面的后向传播算法(BP算法)提供了核心条件。
- 输出范围有限:一般是限定在[0,1],有限的输出范围使得神经元对于一些比较大的输入也会比较稳定。
- 非饱和性:饱和就是指,当输入比较大的时候,输出几乎没变化了,那么会导致梯度消失!梯度消失带来的负面影响就是会限制了神经网络表达能力。sigmoid,tanh函数都是软饱和的,阶跃函数是硬饱和。软是指输入趋于无穷大的时候输出无限接近上线,硬是指像阶跃函数那样,输入非0输出就已经始终都是上限值。关于数学表示**传送门** 里面有详细写到。如果激活函数是饱和的,带来的缺陷就是系统迭代更新变慢,系统收敛就慢,当然这是可以有办法弥补的,一种方法是使用交叉熵函数作为损失函数。ReLU 是非饱和的,效果挺不错。
- 单调性:即导数符号不变。导出要么一直大于0,要么一直小于0,不要上蹿下跳。导数符号不变,让神经网络训练容易收敛。
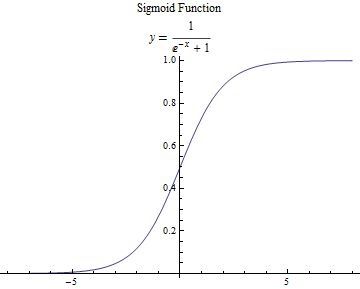
这里用到Sigmoid函数方便理解:
Sigmoid函数:$$y = \frac{1}{e^{(-x)}+1}$$
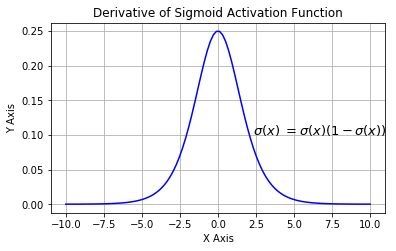
S函数的导数:
$$
\begin{aligned}
&y’= (\frac{1}{e^{-x}+1})’ \\
&=(\frac{u}{v})’,这里u=1,v=e^{-x}+1 \\
&=\frac{u’v-uv’}{v^2} \\
&=\frac{1’\ast (e^{-x}+1)-1\ast (e^{-x}+1)’}{(e^{-x}+1)^2} \\
&=\frac{e^{-x}}{(e^{-x}+1)^2} \\
&=\frac{1}{1+e^{-x}}\ast \frac{1+e^{-x}-1}{1+e^{-x}} \\
&=\frac{1}{1+e^{-x}}\ast (1-\frac{1}{1+e^{-x}}), 令y=\frac{1}{e^{-x}+1} \\
&=y\ast (1-y)
\end{aligned}
$$
S函数的导数的图像:
传播过程
下面是一个典型的三层神经网络结构,第一层是输入层,第二层是隐藏层,第三层是输出层。
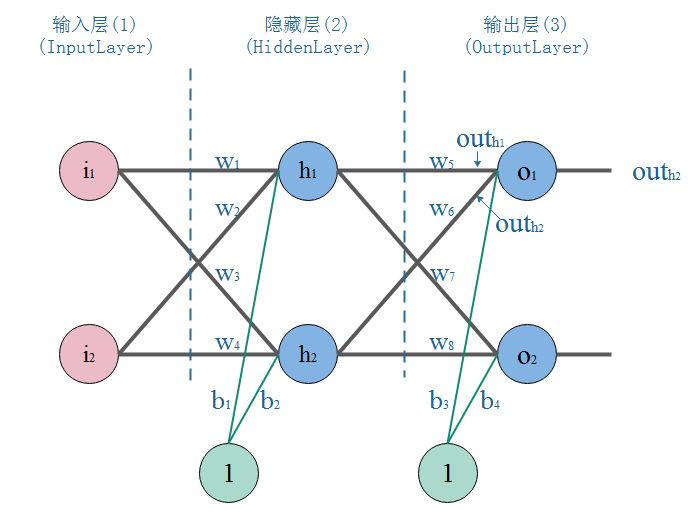
- 正向传播:输入$i_1,i_2$数据,然后一层一层传播下去,知道输出层输出结果。
- 反向传播:输入、期望的输出为已知。在开始时,权重$w$,偏置$b$初始化为随机值,按网络计算后观察结果。根据结果的误差(也叫损失),调整权重$w$,偏置$b$,这时就完成了一次反向传播。
- 当完成了一次正反向传播,也就完成了一次神经网络的训练迭代,反复迭代,误差越来越小,直至训练完成。
BP算法推导和数值计算
初始化参数
- 输入:$i_1=0.1,i_2=0.2$
- 输出:$O_1=0.01,O_2=0.99,(训练时的输出期望值)$
- 权重:$ \begin{aligned} &w_1=0.1,w_2=0.2,w_3=0.3,w_4=0.4 \\ &w_5=0.5,w_6=0.6,w_7=0.7,w_8=0.8 \\ &(这些权重是随机初始化的,通过多次迭代训练调整直到训练完成)\end{aligned} $
- 偏置:$b_1=0.55,b_2=0.56,b_3=0.66,b_4=0.67 \\ (同随机初始化)$
正向传播
- 输入层–>隐藏层:
- 计算隐藏层神经元$h_1$的输入加权和:$$\begin{aligned} IN_{h1}&=w_1\ast i_1+w_2\ast i_2+1\ast b_1 \\ &=0.1\ast 0.1+0.2\ast 0.2+1\ast 0.55 \\ &=0.6\end{aligned}$$
- 计算隐藏层神经元$h_1$的输出,要通过激活函数Sigmoid处理:$$OUT_{h1}=\frac{1}{e^{-IN_{h1}}+1} \ =\frac{1}{e^{-0.6}+1} \ =0.6456563062$$
- 同理计算出隐藏层神经元$h_2$的输出:$$OUT_{h2}=0.6592603884$$
- 隐藏层–>输出层:
- 计算输出层神经元$O_1$的输入加权和:$$\begin{aligned}IN_{O_1}&=w_5\ast OUT_{h_1}+w_6\ast OUT_{h_2}+1\ast b_3 \\ &=0.5\ast 0.6456563062+0.6\ast 0.6592603884+1\ast 0.66 \\ &=1.3783843861\end{aligned}$$
- 计算输出层神经元$O_1$的输出:$$OUT_{O_1}=\frac{1}{e^{-IN_{O_1}}+1} \ =\frac{1}{e^{-1.3783843861}}\ =0.7987314002 $$
- 同理计算出输出层神经元$O_2$的输出:$$OUT_{O_2}=0.8374488853$$
正向传播结束,可以看到输出层输出的结果:$[0.7987314002,0.8374488853]$,但是训练数据的期望输出是$[0.01,0.99]$,相差太大,这时就需要利用反向传播,更新权重$w$,然后重新计算输出。
反向传播
计算输出误差:
误差计算:$$\begin{aligned} E_{total}&=\sum_{i=1}^2E_{OUT_{O_i}} \\ &=E_{OUT_{O_1}} + E_{OUT_{O_2}} \\ &=\frac{1}{2}(expected_{OUT_{O_1}}-OUT_{O_1})^2+\frac{1}{2}(expected_{OUT_{O_2}}-OUT_{O_2})^2 \\ &=\frac{1}{2}\ast (O_1-OUT_{O_1})^2+\frac{1}{2}\ast (O_2-OUT_{O_2})^2 \\ &=\frac{1}{2}\ast (0.01-0.7987314002)^2+\frac{1}{2}\ast (0.99-0.8374488853)^2 \\ &=0.0116359213+0.3110486109 \\ &=0.3226845322 \\ &其中:E_{OUT_{O_1}}=0.0116359213,E_{OUT_{O_2}}= 0.3110486109 \end{aligned}$$
PS:这里使用这个简单的误差计算便于理解,实际上其效果有待提高。如果激活函数是饱和的,带来的缺陷就是系统迭代更新变慢,系统收敛就慢,当然这是可以有办法弥补的,一种方法是使用交叉熵函数作为损失函数。这里有更详细的介绍。
交叉熵损失函数:$$E_{total}=\frac{1}{m}\sum_{i=1}^m(O_i\cdot log OUT_{O_i}+(1-O_i)\cdot log(1-OUT_{O_i}))$$
对输出求偏导:$$\frac{\partial E_{total}}{\partial OUT_{O_i}}=\frac{1}{m}\sum_{i=1}^m(\frac{O_i}{OUT_{O_i}}-\frac{1-O_i}{1-OUT_{O_i}})$$
隐藏层–>输出层的权重的更新:
链式求导法则(详细可参考这篇文章:$$假设y是u的函数,而u是x的函数:y=f(u),u=g(x) \\ 那么对应的复合函数就是:y=f(g(x)) \\ 那么y对x的导数则有:\frac{dy}{dx}=\frac{dy}{du}\cdot \frac{du}{dx}$$
以权重$w_5$举例计算:权重$w$的大小能直接影响输出,$w$不合适会使输出有误差。要知道某个$w$对误差影响的程度,可以用误差对该$w$的变化率来表达。如果$w$的很少的变化,会导致误差增大很多,说明这个$w$对误差影响的程度就更大,也就是说,误差对该$w$的变化率越高。而误差对$w$的变化率就是误差对$w$的偏导。如图,总误差的大小首先受输出层神经元$O_1$的输出影响,继续反推,$O_1$的输出受它自己的输入的影响,而它自己的输入会受到$w_5$的影响。
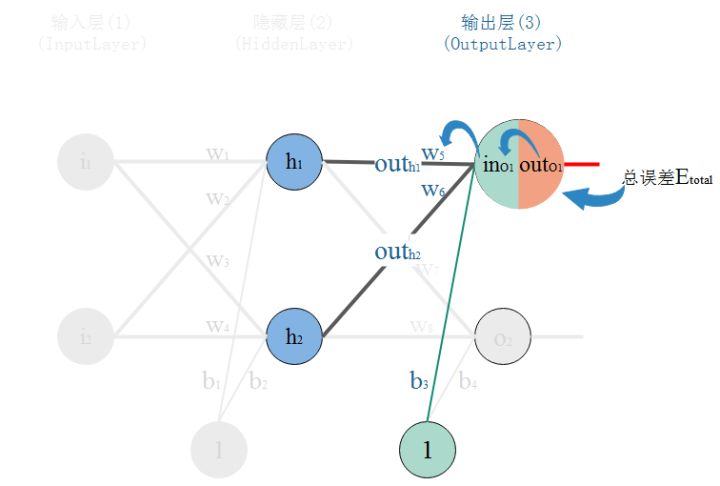
那么根据链式法则有:$$\begin{aligned} \frac{\partial E_{total}}{\partial w_5}&=\frac{\partial E_{total}}{\partial OUT_{O_1}}\frac{\partial OUT_{O_1}}{\partial IN_{O_1}}\frac{\partial IN_{O_1}}{\partial w_5}\end{aligned} $$
第一部分: $$ \begin{aligned} \because E_{total}&=\frac{1}{2}(O_1-OUT_{O_1})^2+\frac{1}{2}(O_2-OUT_{O_2})^2 \\ \therefore \frac{\partial E_{total}}{\partial OUT_{O_1}}&=\frac{\partial (\frac{1}{2}(O_1-OUT_{O_1})^2+\frac{1}{2}(O_2-OUT_{O_2})^2)}{\partial OUT_{O_1}} \\ & =2\ast \frac{1}{2}(O_1-OUT_{O_1})^{2-1}\ast (0-1)+0 \\ & =-(O_1-OUT_{O_1}) \\ & =-(0.01-0.7987314002) \\ & =0.7887314002 \end{aligned}$$
第二部分:$$\begin{aligned}\because OUT_{O_1}&=\frac{1}{e^{-IN_{O_1}}+1} \\ \therefore \frac{\partial OUT_{O_1}}{\partial IN_{O_1}}&=\frac{\partial (\frac{1}{e^{-IN_{O_1}}+1})}{\partial IN_{O_1}} \\ & =OUT_{O_1}(1-OUT_{O_1}) \\ &=0.7987314002*(1-0.7987314002) \\ &=0.1607595505 \end{aligned}$$
第三部分:$$\begin{aligned} \because IN_{O_1}&=w_5\ast OUT_{h_1}+w_6\ast OUT_{h_2}+1\ast b_3 \\ \therefore \frac{\partial IN_{O_1}}{\partial w_5}&=\frac{\partial (w_5\ast OUT_{h_1}+w_6\ast OUT_{H}+1\ast b_3)}{\partial w_5} \\ &=1\ast w_5^{(1-1)}\ast OUT_{h_1}+0+0 \\ &=OUT_{h_1} \\ &=0.6456563062\end{aligned}$$
所以:$$\begin{aligned}\frac{\partial E_{total}}{\partial w_5}&=\frac{\partial E_{total}}{\partial OUT_{O_1}}\frac{\partial OUT_{O_1}}{\partial IN_{O_1}}\frac{\partial IN_{O_1}}{\partial w_5} \\ &=0.7887314002\ast 0.1607595505\ast 0.6456563062\\ &=0.0818667051\end{aligned}$$
归纳如下:$$\begin{aligned}\frac{\partial E_{total}}{\partial w_5}&=\frac{\partial E_{total}}{\partial OUT_{O_1}}\frac{\partial OUT_{O_1}}{\partial IN_{O_1}}\frac{\partial IN_{O_1}}{\partial w_5} \\ &=-(O_1-OUT_{O_1})\cdot OUT_{O_1}\cdot (1-OUT_{O_1})\cdot OUT_{h_1}\\ &=\sigma_{O_1}\cdot OUT_{h_1} \\ & 其中,\sigma_{O_1}=-(O_1-OUT_{O_1})\cdot OUT_{O_1}\cdot (1-OUT_{O_1})\end{aligned}$$
隐藏层–>输出层的偏置的更新:
同理输出层偏置b更新如下:$$\begin{aligned} IN_{O_1}&=w_5\ast OUT_{h_1}+w_6\ast OUT_{h_2}+1\ast b_3 \\ \frac{\partial IN_{O_1}}{\partial b_3}&=\frac{w_5\ast OUT_{h_1}+w_6\ast OUT_{h_2}+1\ast b_3}{\partial b_3} \\ &=0+0+b_3^{(1-1)} \\&=1 \end{aligned}$$
所以:$$\begin{aligned}\frac{\partial E_{total}}{\partial b_3}&=\frac{\partial E_{total}}{\partial OUT_{O_1}}\frac{\partial OUT_{O_1}}{\partial IN_{O_1}}\frac{\partial IN_{O_1}}{\partial b_3} \\ &=0.7887314002\ast 0.1607595505\ast 1\\ &=0.1267961053\end{aligned}$$
归纳如下: $$\begin{aligned} \frac{\partial E_{total}}{\partial b_3}&=\frac{\partial E_{total}}{\partial OUT_{O_1}}\frac{\partial OUT_{O_1}}{\partial IN_{O_1}}\frac{\partial IN_{O_1}}{\partial b_3}\\ &=-(O_1-OUT_{O_1})\cdot OUT_{O_1}\cdot (1-OUT_{O_1})\cdot 1\\ &=\sigma_{O_1}\\ &其中,\sigma_{O_1}=-(O_1-OUT_{O_1})\cdot OUT_{O_1}\cdot (1-OUT_{O_1}) \end{aligned}$$
更新$w_5$的值:
- 暂时设定学习率为0.5,学习率不宜过大也不宜过小,这篇文章学习率有更为详细的介绍,更新$w_5$:$$\begin{aligned}w_5^+&=w_5-\alpha \cdot \frac{\partial E_{total}}{\partial w_5} \\ &=0.5-0.5\ast 0.0818667051\\ &=0.45906664745\end{aligned}$$
- 同理可以计算出其他$w_n$的值
- 归纳输出层$w$的更新公式:$$\begin{aligned}w_O^+&=w_o-\alpha \cdot (-OUT_O\cdot (1-OUT_O)\cdot (O-OUT_O)\cdot OUT_h)\\ &=w_O+\alpha \cdot (O-OUT_O)\cdot OUT_O\cdot (1-OUT_O)\cdot OUT_h\end{aligned}$$
更新$b_3$的值:
- 更新偏置b:$$\begin{aligned}b_3^+&=b_{O_3}-\alpha \cdot \frac{\partial E_{total}}{\partial b_{O_3}} \\ &=0.66-0.5\cdot 0.1267961053\\ &=0.596601947 \end{aligned}$$
- 归纳如下:$$\begin{aligned}b_O^+&=b_O-\alpha \cdot(-OUT_O\cdot(1-OUT_O)\cdot(O_OUT_O))\\ &=b_O+\alpha \cdot (O-OUT_O)\cdot OUT_O\cdot(1-OUT_O)\end{aligned}$$
输入层–>隐藏层的权值更新:
- 以权重$w_1$举例计算:在求$w_5$的更新,误差反向传递路径输出层–>隐层,即$OUT_{O_1}\rightarrow IN_{O_1}\rightarrow w_5$,总误差只有一条路径能传回来。但是求$w_1$时,误差反向传递路径是隐藏层–>输入层,但是隐藏层的神经元是有2条的,所以总误差沿着2个路径回来,也就是说,计算偏导时,要分开来算。
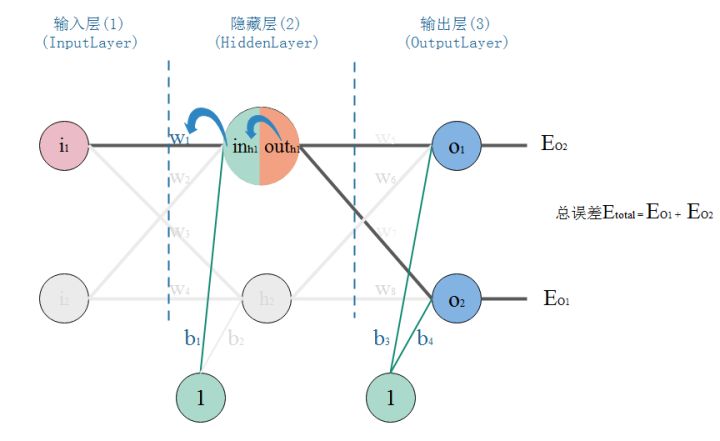
计算总误差对$w_1$的偏导:
$$
\begin{aligned}\frac{\partial E_{total}}{\partial w_1}&=\frac{\partial E_{total}}{\partial OUT_{h_1}}\cdot \frac{\partial OUT_{h_1}}{\partial IN_{h_1}}\cdot \frac{\partial IN_{h_1}}{\partial w_1} \\ &=(\frac{\partial E_{O_1}}{\partial OUT_{h_1}}+\frac{\partial E_{O_2}}{\partial OUT_{h_1}})\cdot \frac{\partial OUT_{h_1}}{\partial IN_{h_1}}\cdot \frac{\partial IN_{h_1}}{\partial w_1}\end{aligned}
$$
- 计算$E_{O_1}对OUT_{h_1}$的偏导:$$\begin{aligned}\frac{\partial E_{total}}{\partial OUT_{h_1}} &= \frac{\partial E_{O_1}}{\partial OUT_{h_1}}+\frac{\partial E_{O_2}}{\partial OUT_{h_1}}\\ \frac{\partial E_{O_1}}{\partial OUT_{h_1}}&=\frac{\partial E_{O_1}}{\partial IN_{O_1}}\cdot\frac{\partial IN_{O_1}}{\partial OUT_{h_1}} \\ (左边)\frac{\partial E_{O_1}}{\partial IN_{O_1}}&=\frac{\partial E_{O_1}}{\partial OUT_{O_1}}\cdot\frac{\partial OUT_{O_1}}{\partial IN_{O_1}}\\ &=\frac{\frac{1}{2}(O_1-OUT_{O_1})^2}{\partial OUT_{O_1}}\cdot \frac{\partial OUT_{O_1}}{\partial IN_{O_1}}\\ &=-(O_1-OUT_{O_1})\cdot \frac{\partial OUT_{O_1}}{\partial IN_{O_1}}\\ &=0.7987314002\ast 0.1607595505\\ &=0.1284037009\\IN_{O_1}&=w_5\ast OUT_{h_1}+w_6\ast OUT_{h_2}+1\ast b_3\\ (右边)\frac{\partial IN_{O_1}}{\partial OUT_{h_1}}&=\frac{\partial (w_5\ast OUT_{h_1}+w_6\ast OUT_{h_2}+1\ast b_3)}{\partial OUT_{h_1}}\\ &=w_5\ast OUT_{h_1}^{(1-1)}+0+0\\ &=w_5=0.5 \\ \frac{\partial E_{O_1}}{\partial OUT_{h_1}} &=\frac{\partial E_{O_1}}{\partial IN_{O_1}}\cdot \frac{\partial IN_{O_1}}{\partial OUT_{h_1}}\\ &=0.1284037009\ast 0.5=0.06420185045\end{aligned}$$
- j计算$E_{O_2}对OUT_{h_1}$的偏导:$$\begin{aligned}\frac{\partial E_{O_2}}{\partial OUT_{h_1}}&=\frac{\partial E_{O_2}}{\partial IN_{O_2}}\cdot\frac{\partial IN_{O_2}}{\partial OUT_{h_1}}\\ &=-(O_2-OUT_{O_2})\cdot \frac{\partial OUT_{O_2}}{\partial IN_{O_2}}\cdot \frac{\partial IN_{O_2}}{\partial OUT_{h_1}}\\ &=-(O_2-OUT_{O_2})\cdot OUT_{O_2}(1-OUT_{O_2})\cdot w_7\\ &=-(0.99-0.8374488853)\ast 0.8374488853\ast (1-0.8374488853)\ast 0.7=-0.0145365614\end{aligned}$$
- 则$E_{total}对OUT_{h_1}$的偏导为:$$\begin{aligned}\frac{\partial E_{total}}{\partial OUT_{h_1}} &= \frac{\partial E_{O_1}}{\partial OUT_{h_1}}+\frac{\partial E_{O_2}}{\partial OUT_{h_1}}\\ &=0.06420185045+(-0.0145365614)=0.04966528905\end{aligned}$$
- 计算$OUT_{h_1}$对$IN_{h_1}$的偏导:$$\begin{aligned}\because OUT_{h_1}&=\frac{1}{e^{-IN_{h_1}}+1} \\ \therefore \frac{\partial OUT_{h_1}}{\partial IN_{h_1}}&= \frac{\partial (\frac{1}{e^{-IN_{h_1}}+1})}{\partial IN_{h_1}} \\ &=OUT(1-OUT_{h_1})\\ &=0.6456563062\ast (1-0.6456563062)=0.2298942405 \end{aligned}$$
- 计算$IN_{h_1}对w_1$的偏导:$$\begin{aligned}\frac{\partial IN_{h_1}}{\partial w_1}&=\frac{\partial(w_1\ast i_1+w_2\ast i_2+1\ast b)}{\partial w_1}\\ &=w_1^{(1-1)}\ast i_1+0+0=i_1=0.1\end{aligned}$$
- 三者相乘计算$E_{total}$对$w_1$的偏导:$$\begin{aligned}\frac{\partial E_{total}}{\partial w_1}&=\frac{\partial E_{total}}{\partial OUT_{h_1}}\cdot \frac{\partial OUT_{h_1}}{\partial IN_{h_1}}\cdot \frac{\partial IN_{h_1}}{\partial w_1}\\ &=0.04966528905\ast 0.2298942405\ast 0.1=0.0011362635\end{aligned}$$
- 归纳:$$\begin{aligned}\frac{\partial E_{total}}{\partial w_1}&=\frac{\partial E_{total}}{\partial OUT_{h_1}}\cdot \frac{\partial OUT_{h_1}}{\partial IN_{h_1}}\cdot \frac{\partial IN_{h_1}}{\partial w_1}\\ &=(\frac{\partial E_{O_1}}{\partial OUT_{h_1}}+\frac{\partial E_{O_2}}{\partial OUT_{h_1}})\cdot \frac{\partial OUT_{h_1}}{\partial IN_{h_1}}\cdot \frac{\partial IN_{h_1}}{\partial w_1}\\ &=(\sum_{n=1}^2\frac{\partial E_{O_n}}{\partial OUT_{O_n}}\cdot\frac{\partial OUT_{O_n}}{\partial IN_{O_n}}\cdot \frac{\partial IN_{O_n}}{\partial OUT_{h_n}})\cdot \frac{\partial OUT_{h_1}}{\partial IN_{h_1}}\cdot \frac{\partial IN_{h_1}}{\partial w_1}\\ &=(\sum_{n=1}^2\sigma_{O_n}w_{O_n})\cdot OUT_{h_n}(1-OUT_{h_n})\cdot i_1\\ &=\sigma_{h_1}\cdot i_1\\&其中,\sigma_{h_1}=(\sum_{n=1}^2\sigma_{O_n}w_{O_n})\cdot OUT_{h_1}(1-OUT_{h_1})\\&\sigma_{O_i}看作输出层的误差,误差和w相乘,相当于通过w传播了过来;如果是深层网络,隐藏层数量>1,那么公式中的\sigma_{O_n}写为\sigma_{h_n},w_O写成w_h\end{aligned}$$
- 现在更新$w_1$的值:$$\begin{aligned}w_1^+&=w_1-\alpha\cdot \frac{\partial E_{total}}{\partial w_1}\\ &=0.1-0.1\ast 0.0011362635=0.0998863737\end{aligned}$$
- 归纳隐藏层$w$更新的公式:$$\begin{aligned}w_h^+&=w_h-\alpha\cdot \frac{\partial E_{total}}{\partial w}\\ &=w_h+\alpha\cdot (-\sum_{n=1}^2\sigma_{O_n}w_{O_n})\cdot OUT_{h_n}(1-OUT_{h_n})\cdot i_1\end{aligned}$$
计算隐藏层偏置b的更新:
$$
\begin{aligned}\frac{\partial E_{total}}{\partial b_h}&=(\sum_h\sigma_hw_h)\cdot OUT_h(1-OUT_h)\\ b_h^+&=b_h-\alpha\cdot \frac{\partial E_{total}}{\partial b_n}\\ &=w_h+\alpha\cdot (\sum_h\sigma_hw_h)\cdot OUT_h(1-OUT_h)\end{aligned}
$$
代码实现
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!